머신러닝(Machine Learning) 7장
- Multinomial classification -
앞장에서 Logistic regression에 대한 설명을 하였는데 잠깐 요약하게 되면 Logistic regression 중 binary 결과 값에 대한 예측을 진행하였다. 0과 1에 중에 하나의 값을 결과 값으로 가져야하는데 Linear regression을 사용하게 되면 선형적으로 결과 값이 증가하거나 감소하기 때문에 결과 값을 나타내기 힘들었다. 따라서 sigmoid function을 이용하여 결과 값이 0과 1 사이에서만 나타나게 만들고 0.5의 기준을 가지고 0인지 1인지를 구분하게 되었다. 그런데 여기서 결과 값이 0과 1만이 아니라 학점과 같이 A, B, C, D, F 와 같은 형태로 다양하게 가져야 한다면 어떻게 예측을 할 수 있을까?
먼저 Logistic regression의 원리를 조금 더 파헤쳐보자. Logistic regression은 원래 선형적으로 나누는 데이터에 대한 결과를 다시 sigmoid function을 통해 0과 1사이의 값으로 바꾸어주는 것이다. 따라서 실제 데이터인 x1과 x2로 만들어진 그래프를 보게 되면 다음과 같이 나눌 수 있다. 네모의 형태를 가지는 것을 1로 엑스의 형태를 가지는 것들을 0으로 만들어서 둘을 구분해주는 것이다. 실제로는 두 데이터를 구분시켜주는 선형을 가지고 그에 대한 데이터 값들을 sigmoid function을 통해 0과 1로 구분해주는 것이다.
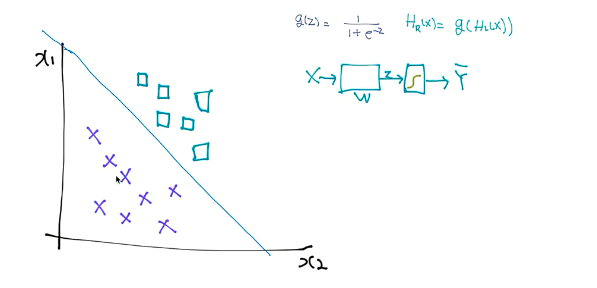
그러면 결과 값이 0과 1이 아닌 데이터에 대해서도 생각을 할 수 있을 것이다. A와 B, C에 대한 결과 값을 가지는 데이터가 있다고 가정해보자. 그래프에 표시를 하여 데이터를 나타낼 수 있을 것이다.

그래프의 데이터를 각각의 데이터 하나에 대해 나머지 데이터와 구분을 짓는 binary한 형태로 생각할 수 있을 것이다. 예를 들면 A인 결과 값과 나머지를 생각하고 다른 경우는 B인 경우와 나머지들, 마지막으로 C인 경우와 나머지를 구분시켜주는 binary classification을 생각할 수 있다. 이런 경우를 각각 학습시켜 충분히 결과 값을 구분 지어줄 수 있는 알고리즘이 가능하다.
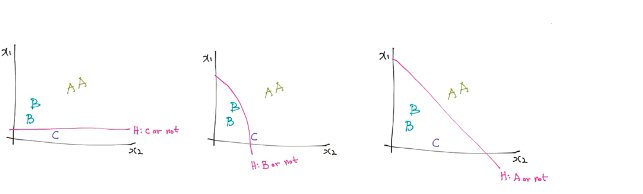
따라서 독립적으로 하나하나의 데이터를 세 번의 결과로 계산을 해서 어디에 속하는지를 판별할 수 있게 된다. 앞장에서 사용했듯이 행렬의 형태를 사용하면 쉽게 나타낼 수 있고 실제 코드를 사용할 때 쉽게 실행시킬 수 있게 된다. 결과 값은 바로 H(x)의 각각 결과 값에 대한 형태로 나타나게 된다. 이 값에 대해서 우리는 sigmoid function을 이용하여 0과 1사이의 값을 만들게 만들어 줘야한다.

다음 장에서는 위와 같은 형태의 알고리즘을 조금 더 편하게 sigmoid function에 적용시킬 수 있는지와 cost function에 대해 알아볼 것이다.
출처: https://copycode.tistory.com/163?category=740659 [ITstory]
'자료' 카테고리의 다른 글
| 머신러닝(Machine Learning) 9장 - Learning rate, data preprocessing, overfitting (0) | 2020.07.08 |
|---|---|
| 머신러닝(Machine Learning) 8장 - Softmax regression의 cost함수 (0) | 2020.07.08 |
| 머신러닝(Machin Learning) 6장 - Logistic Regression 의 cost function (0) | 2020.07.08 |
| 머신러닝(Machine Learning) 5장 - Logistic (Regression) Classification (0) | 2020.07.08 |
| 머신러닝(Machine Learning) 4장 - Multi-variable Linear regression (0) | 2020.07.08 |



